Im Zusammenhang mit dem OpenData-Projekt “Offenes Ratsinformationssystem” müssen viele Daten von offiziellen Stadt-Websites abgegriffen und verarbeitet werden. Mit diesem Blogpost möchte ich einen kleinen Blick in den Maschinenraum werfen und zeigen, wo die Daten “entlangfließen”.
Das Problem: Keine Schnittstelle
Wenn man Daten verarbeiten möchte, so möchte man am liebsten eine Schnittstelle haben. Eine Schnittstelle stellt Daten strukturiert bereit. Strukturierte Daten sind an sich nicht besonders hübsch lesbar für das menschliche Auge, aber um so besser geeignet für die maschinelle Verarbeitung. Formate dazu wären JSON, XML oder (notfalls) auch CSV. Marian Steinbach hat daher die JSON-Schnittstelle OParl für Ratsinformationssysteme entwickelt. An dieser Schnittstelle kann man auch ein zweites wichtiges Feature einer Schnittstelle erkennen: Dokumentation. Der Programmierer muss wissen, was für Daten ihn erwarten.
Die grafische Oberfläche eines Ratsinformationssystems
Die aktuell auf dem Markt befindlichen Ratsinformationssysteme bieten öffentlich bislang ausschließlich die HTML-Ausgabe. HTML stellt im Idealfall Informationen ebenso strukturiert dar – schließlich ist HTML im Endeffekt auch nur ein XML Dialekt. Die Realität sieht leider anders aus: Die Ausgabe versucht ausschließlich, dem Nutzer mit seinem Webbrowser die Informationen darzustellen – visuell irgendwie sinnvoll, aber nicht strukturiert. Üblicherweise wird auch noch das deutlich veraltete HTML 4.01 verwendet, was um so weniger Möglichkeiten der Struktur bietet, und selbst diese Möglichkeiten werden nicht genutzt.
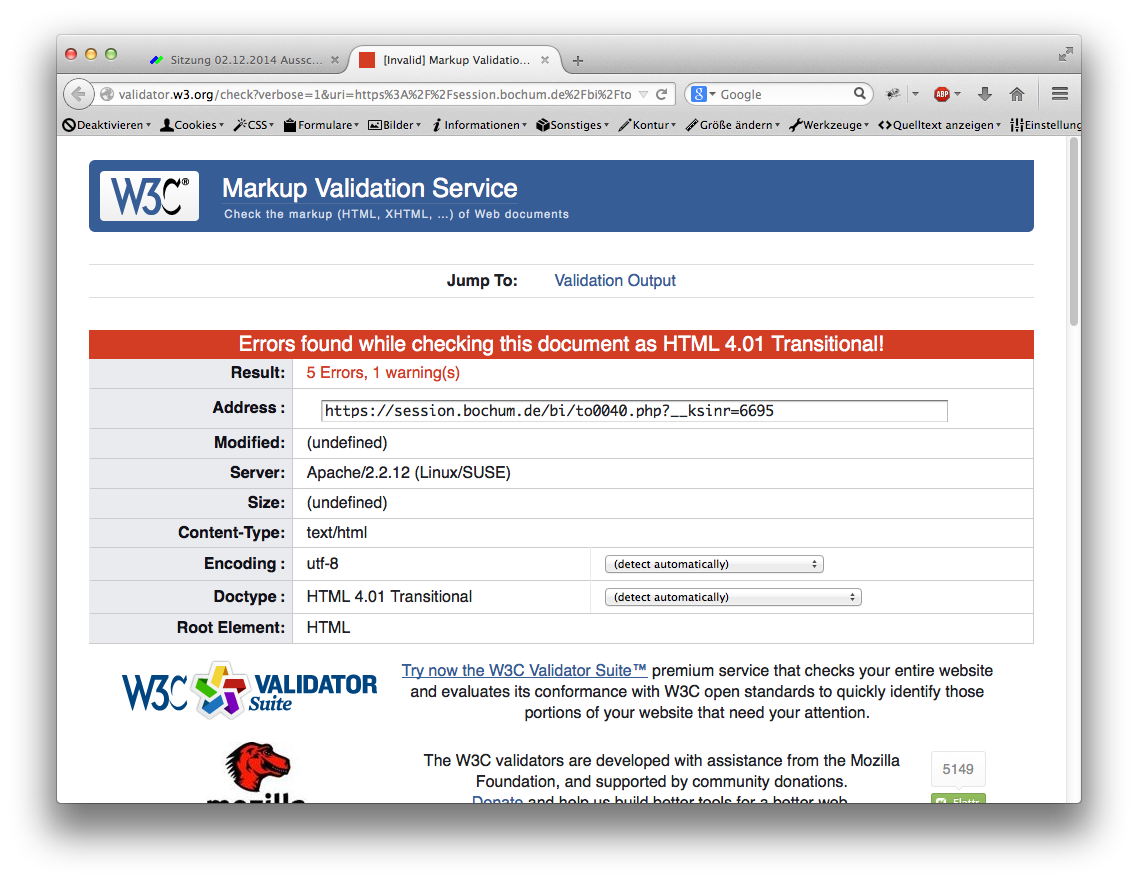
Typische HTML-Fehler in einem Ratsinformationssystem.
Ansatz Nummer 1: HTML-Struktur + CSS-Selektoren (Scraping)
Der mühsamste Ansatz ist, durch die visuelle Ausgabe zu springen und die einzelnen Informationen herauszugreifen. Dafür nutzt man aus, dass die Ratsinformationssysteme IDs und Klassen nutzen, um die HTML-Ausgabe zu layouten. Diese IDs und Klassen bieten oft (aber leider nicht immer) eindeutige Pfade zu der Position der gewünschten Information. Dieser Pfad wird CSS-Pfad genannt. Der XPath kann dabei helfen, er beschreibt die Position einer Information komplett ohne IDs und Klassen.
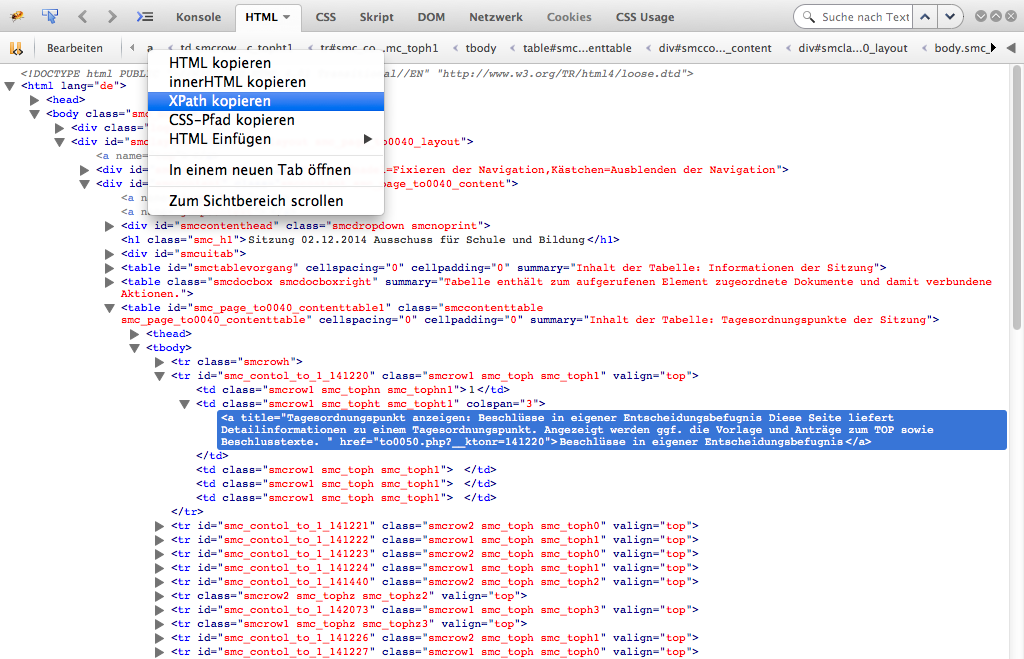
Auswählen einer Information über den XPath.
Mit dem Firefox-Plugin Firebug oder mit der Chrome Entwicklerkonsole kann man den CSS-Pfad einer Information herauskopieren. Dieser ist oftmals recht länglich:
html body.smc_body div#smclayout.smclayout.smc_page_to0040_layout div#smccontent.smccontent.smc_page_to0040_content table#smc_page_to0040_contenttable1.smccontenttable.smc_page_to0040_contenttable tbody tr#smc_contol_to_1_141220.smcrow1.smc_toph.smc_toph1 td.smcrow1.smc_topht.smc_topht1 a
Mit jedem Leerzeichen geht es eine Ebene tiefer. Das direkt nach dem Leerzeichen ist das Element, ein #id (also alles nach der Raute) ist eine ID, ein .klasse (also alles nach dem Punkt) ist eine Klasse. Der Pfad ist leider wenig universell, weil zum Beispiel smc_contol_to_1_141220 eine ID enthält, die so nie auf einer anderen Seite mit ähnlichen Informationen vorkommen wird. Dies ist dann auch die größte Herausforderung: Den CSS-Pfad so universell gestalten, dass er die gewünschten Informationen abgreift, aber eben auch nicht zu viel. Das sieht zum Beispiel so aus:
table#smc_page_to0040_contenttable1 td a
So entstehen die Selektoren, die man in der Konfiguration unter xpath findet. Dies reicht zumeist nicht komplett aus, sodass man die XPath zur Hilfe nimmt und durch die einzelnen Nodes durchspringt und in Unterbereichen des HTML-Dokuments CSS-Selektoren verwendet. Ein Beispiel dazu findet man im SessionNet Scraper: Zunächst wird das HTML als XML eingelesen (in die Variable dom). Dann testet man entweder Werte direkt mit dem Pfad auf die ganze XML (in diesem Fall sucht man sich die Überschrift h1 heraus) – oder aber man wählt sich zunächst einen Unterbereich aus (in diesem Fall alle Tabellenfelder einer bestimmten Tabelle) und verarbeitet die dort enthaltenen Infos anschließend je nach Inhalten (in diesem Fall wird der Name als Kurzname identifiziert und gespeichert).
Leider kann bei dieser Art der Informationsgewinnung so Einiges schiefgehen. Das wohl größte Problem ist, dass sich die Quelle verändert. Wenn das offizielle Ratsinformationssystem ein Update bekommt, sehen die IDs und Klassen eventuell ein ganz klein wenig anders aus – und schon funktioniert das ganze Abgreifen von Informationen nicht mehr.
Aber auch fehlende Felder können ein Problem sein: Oftmals muss man Informationen auf Basis von darüber liegenden Informationen identifizieren, also z.B. die Regel “direkt unter dem Datum folgt die Beschreibung”. Wenn aus irgendeinem Grund das Datum fehlt, schlägt auch die Identifikation der Beschreibung fehl.
Zuletzt ist auch die Menge an Code ein Problem: Auf diesem Weg ist es extrem aufwändig, Informationen abzugreifen. Man muss also für kleinste Ergebnisse viel Arbeit investieren, sodass dies unattraktiv für eine freie Entwicklerszene wird und hohe Kosten bei kommerziellen Aufträgen verursacht.
Es gibt auch einige auf Informations-Scraping spezialisierte Libraries wie Scrapy. Diese können sehr, sehr hilfreich sein, scheitern aber gerne an dem doch sehr veralteten HTML-Code von Ratsinformationssystemen, sodass ich die direkte Variante über XML- und CSS- Selektoren beibehalten habe.
Kurzer Exkurs: Der Fluch von PDF-Anhängen
Und noch etwas: Informationen, welche nur über PDF-Anhang zur Verfügung stehen, sind ein ganz besonderes Problem. Denn dort existieren nicht einmal CSS-Selektoren wie IDs und Klassen. Es ist zum Beispiel de Facto unmöglich, Tagesordnungspunkte von der Seitennummerierung zu unterscheiden, deswegen können Informationen aus PDFs nicht präzise zugeordnet werden.
Um die Suchergebnisse im offenen Ratsinformationssystem nicht allzu sehr zu verfälschen, werden daher bei der Dokumentsuche zugeordnete Tagesordnungen und Protokolle ignoriert: Es ist nicht möglich, festzustellen, ob der Suchbegriff “Baum” zum Tagesordnungspunkt 1 oder 2 gehört. Wenn die Tagesordnung Teil der Suche wäre, würde beim Suchbegriff “Baum” aber beides als Ergebnis kommen, auch wenn es in Tagesordnungspunkt 2 gar nicht um Bäume geht – die Informationen in der PDF kann man aber eben nicht trennen.
Noch schlimmer sind eingescannte PDFs. Dort muss man einen OCR-Scan drüberlaufen lassen, um den Text zu extrahieren, da er nicht direkt in der PDF steht. Dies erzeugt sehr viel Serverlast und ist sehr fehleranfällig – der OCR-Scan muss eben anhand der Bildinformationen raten, welcher Buchstabe in welcher Struktur (Satzzusammenhang, Ausrichtung, …) gemeint sein könnte. Da glücklicherweise viele (aber leider nicht alle) Dokumente der bisher bearbeiteten Städte keine Scans sind, unterstützt das offene Ratsinformationssystem diese Funktion noch nicht.
PDFs sind eben wirklich nur für den Druck richtig gut geeignet. Wenn es eine HTML-Ausgabe gibt, sollte man diese ebenfalls nutzen – damit hilft man nicht nur Programmierern.
Ansatz Nummer 2: Undokumentierte XML-Ausgabe nutzen
Hin und wieder gibt es bei den bestehenden Ratsinformationssystemen XML-Schnittstellen. Diese sind zwar komplett undokumentiert, erleichtern einem das Abgreifen von Informationen aber erheblich. Außerdem sind die Schnittstellen nicht überall aktiv – vermutlich, weil man sie zum Teil dazubuchen muss, da sie eigentlich der serverseitige Teil von Smartphone-Apps sind.
Der zur Zeit nicht funktionsfähige Scraper von AllRis basiert zum Teil auf dieser XML-Schnittstelle. Teilweise, weil nicht alle Informationen über XML bereitgestellt werden – Personen, Gruppen und Gremientreffen ja, Beschlüsse / Paper aber nicht. Für den Rest verwendet man wiederum CSS-Selektoren wie in Ansatz 1 beschrieben.
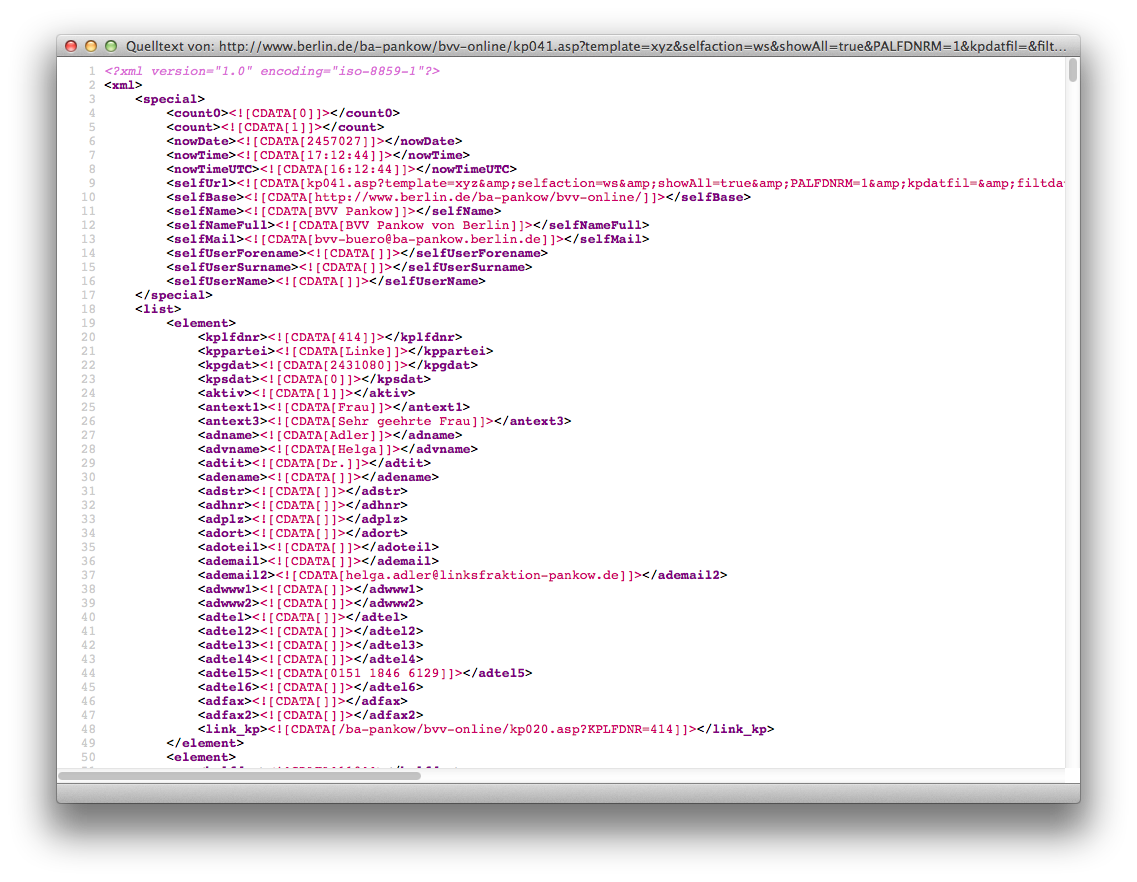
Eine typische XML-Ausgabe, hier aus dem Berliner Bezirk Pankow.
Das Bearbeiten von XML-Ausgaben besteht eigentlich vor allem aus dem Zuordnen von Informationen. Zunächst lädt man die XML-Struktur, dann springt man durch die einzelnen XML-Nodes und greift die einzelnen Informationen ab (in diesem Fall den Vornamen). Da jede Information mit einer (zum Teil kryptischen und leider nicht dokumentierten) Bezeichnung beschriftet ist, kann dabei nicht so viel schiefgehen wie bei Methode 1.
Typische Probleme mit der fehlerhaften XML-Ausgabe von Ratsinformationssystemen.
Leider ist die XML-Ausgabe oft nicht mit Hilfe von XML-Libraries entstanden, sodass die XML-Ausgabe sich nicht an den XML-Standard hält. Dies führt zu Fehlern in der Interpretation der Daten, daher ist ein sehr robuster XML-Parser nötig, um die Informationen korrekt zu interpretieren. Außerdem ist es ein Problem, dass es keine Dokumentation gibt: Die beschreibenden Strings können sich bei Updates ändern, außerdem muss man oft raten, wo sich die XML-Ausgabe versteckt, was die Parameter beim Aufruf bedeuten und welches Feld was bedeutet. Nichtsdestotrotz ist eine fehlerhafte XML-Ausgabe noch immer einfacher als Methode 1.
Weiterverarbeitung der Daten
Oftmals fehlen wichtige Informationen in der HTML-Ausgabe. Zum Beispiel wäre es interessant, in welchem geographischen Zusammenhang ein Antrag steht. Außerdem sind ganz praktische Datenverarbeitungen sinnvoll: Das Generieren von Thumbnails, des Suchindexes, der Rohdatenexports, der XML-Sitemaps oder das Extrahieren von Texten aus PDFs. Die meisten Aufgaben davon sind recht direkt machbar, weil sie einfach nur die in der Datenbank gespeicherten Daten benötigen. Die oben angesprochenen OCR Scans gehören auch in die Kategorie Weiterverarbeitung. Die Geolokalisierung möchte ich aber genauer betrachten, weil sie das Verbinden von Daten behandelt.
Um Daten mit Geoinformationen zu versehen, benötigt man Straßennamen. Diese bekommt man bei OpenStreetMap. Dort liegen die Daten aber pro Regierungsbezirk vor – also muss man zunächst die OSM-Relation-ID nutzen, um die Straßen herauszufiltern, welche tatsächlich zu der Stadt gehören. Dies geschieht über den OSM-Import. Dieser speichert die Straßennamen in die MongoDB ab.
Das Script generate_georeferences.py nimmt dann beide Datenquellen – Ratsinformationssystemdaten plus OSM-Daten – und matcht diese miteinander. Im Einzelnen: Zunächst lädt es alle Straßennamen, generiert Abwandlungen wie Abkürzungen und schaut anschließend, ob eine der Namen in den Textexporten der Anhänge vorkommt.
Abschluss – Mithelfen?
Ich hoffe, dass man mit diesem kleinen Artikel einen Einblick in die Gewinnung von strukturierten Informationen bekommen hat. Wer Lust hat, sich damit intensiver zu beschäftigen – der Scraper für Ratsinformationssysteme freut sich über Patches!
Ein paar Anmerkungen zu zwei Punkten.
1. Zu der Aussage, dass Dokumentation ein “wichtiges Feature einer Schnittstelle” sei. Ein Programmierer müsse “wissen, was für Daten ihn erwarten”.
Tatsächlich wird die Lektüre von Dokumentation von Menschen regelmäßig eher als notwendiges Übel angesehen denn als Nutzung eines Features. Viele gute Programme sind heutzutage so aufgebaut, dass sie ohne Dokumentation verwendbar sind. Und beim Besuch einer Website möchte man auch nicht erst eine Anleitung lesen müssen, um sich dort zurecht zu finden.
Für maschinenlesbare Daten gilt nichts anderes. Das ist einer der Hauptgründe für REST. Und deshalb gibt es Standards wie JSON-LD (und darauf aufsetzende Spezifikationen), die nicht nur eine grundlegende Syntax – JSON – verwenden, sondern mit denen sich zusätzlich auch wesentliche Teile der Semantik von Daten maschinenlesbar beschreiben lassen. Die notwendige Dokumentation für Menschen kann dann sehr kurz gehalten werden – was natürlich nicht ausschliesst, dass man sie zusätzlich für Menschen mit Beispielen illustriert.
Eine solche nachhaltige maschinenlesbare Spezifikation ist ein Ziel des OpenGovLD Projektes, dass im Rahmen der Open Government Community Group des W3C entwickelt wird. Das Vokabular deckt zudem nicht nur deutsche Stadt- oder Gemeinderäte ab, sondern entsprechende Daten wie sie weltweit anfallen. Diese Spezifikation wird deshalb auch die weltweite Verwendung von entsprechender Software ermöglichen – wozu Scraper ebenso gehören wie z.B. Visualisierungsprogramme.
2. Zu den Dokumenten-Formaten.
PDF ist hier in der Tat klar suboptimal. Aber auch für Dokumente aus Gremiensystem werden Spezifikationen entwickelt, mit denen die technische Qualität der Dokumente und die Arbeitsabläufe drastisch verbessert werden können. Dazu gehören insbesondere die Arbeiten an dem auf XML basierenden Akoma Ntoso die inzwischen innerhalb der LegalDocML Arbeitsgruppe von OASIS erfolgen.